Go总结(九)| goroutine+channel并发编程
goroutine
在Go里,每一个并发执行的活动成为goroutine。
当一个程序启动时, 只有一个goroutine来调用main函数,称它为主goroutine。新的goroutine通过go语句进行创建。语法上,一个go语句是在普通的函数或者方法调用前加上go关键字前缀。main函数返回时,main函数中其他所有的goroutine都暴力直接终结,然后程序退出。除了从main返回或者退出程序之外, 没有程序化的方法让一个goroutine来停止另一个。
channel
goroutine 是Go程序并发的执行体,通道就是它们之间的连接。
通道可以让一个 goroutine发送特定值到另一个goroutine的通信机制。每一个通道是一个具体类型的导管, 叫做通道的元素类型。一个有int类型元素的通道写为 chan int。
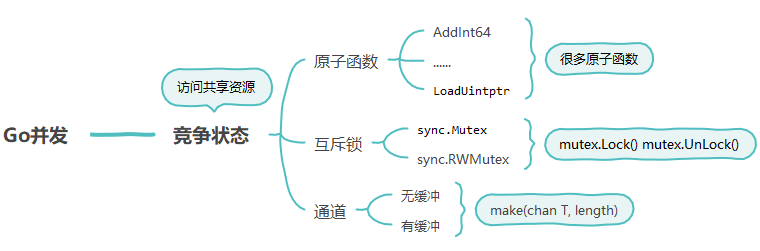
竞争状态
如果两个或者多个goroutine在没有互相同步的情况下,访问某个共享的资源,并试图同时读和写这个资源,就处于相互竞争的状态,这种情况被称作竞争状态(race candition)。竞争状态的存在是让并发程序变得复杂的地方,十分容易引起潜在问题。对一个共享资源的读和写操作必须是原子化的,换句话说,同一时刻只能有一个goroutine对共享资源进行读和写操作。
下面看一个例子:
|
|
运行这段代码,我看到结果是:2 或者 4,其它可能性也是有的。这就是并发带来的问题。
Go工具箱为我们提供了检查代码并发安全问题的工具,在项目所在目录下运行go build -race会得到一个编译好的可执行文件,然后运行他看看会出啥结果;工具告诉我们代码存在并发的问题,我Windows下看到的结果如下:
# go build -race
D:\yufa>yufa.exe
==================
WARNING: DATA RACE
Read at 0x0000009739b8 by goroutine 8:
yufa/demo/go_buf.incCount()
D:/xxx/atomic_func.go:27 +0x84
Previous write at 0x0000009739b8 by goroutine 7:
yufa/demo/go_buf.incCount()
D:/xxx/atomic_func.go:30 +0xa4
Goroutine 8 (running) created at:
yufa/demo/go_buf.Concurrency()
D:/xxx/atomic_func.go:19 +0x7e
main.main()
D:/xxx/main.go:6 +0x36
Goroutine 7 (finished) created at:
yufa/demo/go_buf.Concurrency()
D:/xxx/atomic_func.go:18 +0x66
main.main()
D:/xxx/main.go:6 +0x36
==================
4
Found 1 data race(s)
很显然我们有三种方法解决数据竞态的问题:
- 第一种:不要修改变量。不同的goroutine都只是读取共享变量,当然就没问题了。
- 第二种:避免从多个goroutine访问同一个变量,不同goroutine之间通过通道来同步数据。
- 第三种:不同goroutine可以访问同一个变量,但不能同时访问。这种方法利用互斥锁来保证。
第一种就不说了,很自然就没问题。第二、三种Go有相应的解决办法;为了解决并发编程复杂性的问题,Go语言提供了三种主要的解决办法,如上图所示。下面开始逐一分析。
原子函数
把上面的代码用原子函数包裹一次,你会发现每次运行结果都是4,这就符合预期了。
|
|
使用了atmoic包的AddInt32函数。这个函数会同步整型值的加法,方法是强制同一时刻只能有一个goroutine运行并完成这个加法操作。当goroutine试图去调用任何原子函数时,这些goroutine都会自动根据所引用的变量做同步处理。
另外有一些原子函数如LoadInt64、StoreInt64、LoadInt32、StoreInt32、LoadPointer、StorePointer等。这些函数提供了一种安全地读和写一个对应类型值的方式。
互斥锁
原子函数虽然能解决并发共享数据安全的问题,但这些函数操作数据类型都比较简单,复杂的组合类型或者带有一些逻辑的代码也不大好些;为此Go提供了另外一个sync包,用对代码段加锁解锁的办法来解决;这段代码叫做“临界区”。临界区在同一时刻只能有一个goroutine访问;这段代码就是同步执行的。下面用这种方式对这个例子再做改造。
|
|
这也是比较经典的解决并发访问共享内存的方法。使用起来特别灵活,但是记住锁住的代码段开销尽量小;否则肯定影响性能啊。
还有一种特殊类型的锁叫:读写锁。它允许只读操作可以并发执行,但写操作需要获得完全独享的访问权限,这种锁称为多读单写锁。Go语言中读写锁类型是sync.RWMutex,看下面的例子:
|
|
重点:
仅在绝大部分goroutine都在获取读锁并且锁竞争比较激烈的时(即:goroutine一般都需要等待后才能获取锁),RWMutex才有优势。因为RWMutex需要更复杂的内部记录工作,所以在竞争不激烈的时候他比普通互斥锁还要慢。
通道(channel)
解决并发问题,上面两种方法都比较传统,Go为我们提供了最具特色的办法:通道。
通道,他有点像在两个goroutine之间架设的管道,一个goroutine可以往这个管道里塞数据,另外一个可以从这个管道里取数据,有点类似于我们说的队列。通过发送和接收需要共享的资源,在goroutine之间做同步。
声明通道、向通道发数据、从通道取数据;这些语法很简单:
|
|
上面我们使用make函数初始化的时候,只有一个参数,make还可以有第二个参数,用于指定通道的大小。没有第二个参数的时候,通道默认的大小为0,这种通道也被称为无缓冲通道;如果指定的值大于等于1,这种通道称为有缓冲通道。
|
|
关闭通道
如果一个通道被关闭了,我们就不能往这个通道里发送数据了,发送的话会引起painc异常。不过我们还可以接收通道里的数据,如果通道里没有数据的话,接收的数据是零值,即通道类型对应的默认初始值。
|
|
无缓冲通道
无缓冲的通道指的是通道的大小为0,也就是说,这种类型的通道在接收前没有能力保存任何值,它要求发送goroutine和接收goroutine同时准备好,才可以完成发送和接收操作。
下面用无缓冲通道实现上面的例子:
|
|
这里发送goroutine和接收gouroutine必须是同步的,如果没有同时准备好的话,先执行的操作就会阻塞等待,直到另一个操作发生为止。这种无缓冲的通道也叫同步通道。
管道
管道的应用在我们平时操作Linux系统是随处可见;前一个命令的输出就是后一个命令的输入。Go语言中通道也可以用来模拟管道的效果。
|
|
单向通道
有时候有一些特殊场景,比如限制一个通道只可以接收不能发送;或者限制一个通道只能发送不能接收,这种通道我们称为单向通道。
假如一个通道真的只能读取数据,那么它肯定只会是空的,因为你没机会往里面写数据。同理,如果一个通道只允许写入数据,即使写进去了,也没有丝毫意义,因为没有办法读取到里面的数据。所谓的单向通道概念,其实只是对通道的一种使用限制。
定义单向通道也很简单,只需要在定义的时候,带上<-即可,分别放在chan关键字的前后:
|
|
单向通道有什么意义呢?单向通道应用于函数或者方法的参数比较多,主要是防止通道被外部误操作。看下面代码:
|
|
这里有一个通道类型的隐式转换。将内部双向通道转换成外部只读的单向通道了,对外部暴露只读的通道。
有缓冲通道
有缓冲通道,其实是一个队列,这个队列的最大容量就是我们使用make函数创建通道时,通过第二个参数指定的。
|
|
结果是随机的:
5.chende.ren
2.chende.ren
1.chende.ren
3.chende.ren
4.chende.ren
对于有缓冲的通道,向其发送操作就是向队列的尾部插入元素,接收操作则是从队列的头部删除元素,并返回这个刚刚删除的元素。当队列满的时候,发送操作会阻塞;当队列空的时候,接受操作会阻塞。有缓冲的通道,不要求发送和接收操作是同步的,相反可以解耦发送和接收操作。
有缓冲通道有一个比较有意义的例子:想获取服务端的一个数据,不过这个数据在三个镜像站点上都存在,这三个镜像分散在不同的地理位置,而我们的目的又是想最快的获取到数据。这里我们定义一个容量为3的通道responses,然后同时发起3个并发goroutine向这三个镜像获取数据,获取到的数据发送到通道responses中,最后我们使用return <-responses返回获取到的第一个数据,也就是最快返回的那个镜像的数据。
通道大小
想知道通道的容量以及里面有几个元素数据怎么办?其实和map一样,使用cap和len函数就可以了。
结语
Go语言引入了原子函数、互斥锁、通道;主要是这三种方法解决并发访问共享变量的问题;掌握这些语言特性,对编写高并发的应用程序非常有用。这里引发一个思考,这些三种使用方式究竟哪一种的性能最好呢?
(完)
- 原文作者: 闪电侠
- 原文链接:https://chende.ren/2020/12/28140907-009-concurrency.html
- 版权声明:本作品采用 开放的「署名 4.0 国际 (CC BY 4.0)」创作共享协议 进行许可