Go总结(八)| 运行时调度器模型GMP
Go语言最大的特色就是其并发编程模型,多处理器的时候还可以自动实现真正的并行计算。这些复杂的调度算法被打包在了Go语言运行时当中。
分时调度
先回顾一下操作系统。
操作系统本身就是对硬件资源的一个大调度器;如果没有多任务的需求,我们都不需要这么复杂的调度,不需要分时操作系统;一直算个不停,一条路走到黑反而是利用率最高的;事实上最早期的操作系统就是实时操作系统,无法处理多任务。
可是由于CPU和IO设备(待办事项)的性能根本就不在同一个世界,一个在天上飞,一个在地上爬;想让他们哥两合作一起干活,CPU大部分时间只能喝茶了,这不就是资源浪费么!
而实际情况却是,待处理的IO任务又很多,大家都排着队去找CPU帮忙呢。于是聪明的人就开始琢磨了,既然CPU你这么快这么能干,我就把你的时间给分成一片一片的,你每个时间片就去处理一项任务。结果你发现所有任务几乎都在同时进行,因为CPU太快了,你都感觉不到他是分时处理不同任务的。给CPU时间分片,调度不同任务给CPU处理的这个工作就是操作系统干的,他是计算机系统的大管家。
分层设计,调度算法的设计几乎贯穿于整个计算机世界的不同角落。
进程和线程
为了方便的管理这些待执行的任务,也考虑到隔离安全、执行效率等诸多问题,操作系统搞出进程和线程的概念。
下面用图来解释一下进程和线程:
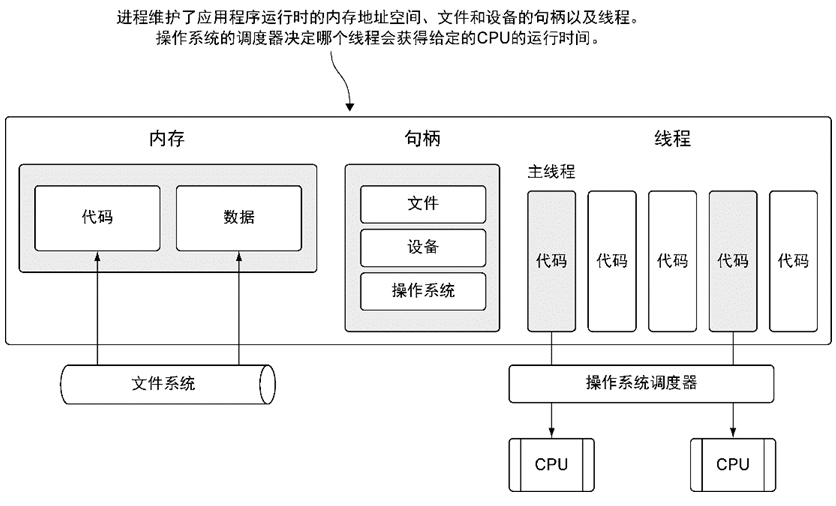
进程是一个程序运行所独自占用系统资源的集合。每个进程都必须至少有一个主线程;线程负责运行具体的计算指令,是操作系统最小的调度单元。一个进程可能是一项复杂的任务,可以拆解成更多子任务来并行执行,于是操作系统允许进程创建更多可以并行执行的子任务交给自己来调度,究竟如何调度资源为每个子任务服务,完全是操作系统说了算。
操作系统支持的这套模型的确提高了资源利用率,在很大程度上也提供了让进程可以自由拆分子任务的手段,能够提高进程处理任务的性能。
与此同时带来了复杂度。并行的线程会涉及到共享资源的问题,最典型就是共享内存;都要访问就竞争,为了安全就加锁,你加了锁别人就只能干等你先解锁,锁来锁去弄不好就死锁(搞死了谁也别想好过)…就这样极大的提高了问题的复杂度,给编程人员带来了挑战;当然善于处理这些麻烦事的程序员就要涨工资啦!
Node.js
有些技术架构为了规避这些问题,干脆就放弃了多线程,直接一个主线程打天下,比如Node.js。他直接建立几个任务队列,凭借CPU的高效运行,直接挨个处理队列中的每个任务;该计算的就给你计算完,轮到IO的时候就把你丢到IO线程池去处理,自己处理下一个在排队的任务,队列处理完了就等着下一个可处理任务的到来;IO线程池中的任务待资源就绪之后自动加入可处理队列,同时通过异步回调的方式通知主线程我又回来了,Node.js主线程发现有任务又开始忙碌起来…
Node.js这套设计其实是简单直接高效的,他不涉及到大量线程的CPU时间片切换。但有个致命的弱点,他擅长处理IO密集型的任务,CPU稍微密集一些,主线程就会来不及处理后面排队的任务,当新任务源源不断来的时候,就出现雪崩效应,程序就卡死了。
为了避免这种情况的出现,自然会想到一个进程不行,我就同时启动多个进程做负载均衡,充分利用多核资源嘛;于是就出现了NodeCluster;这很大程度上解决了Node.js单线程(只有一个主线程处理所有请求的队列)的问题。
可是Node.js这种高效的处理方式,并没有在服务器端开发中大放异彩,被更多人在服务器端开发中大量采用。我想跟这种技术方案并没有很大的关系,而是语言的问题,JS的历史包袱太重,语言的灵活性给代码安全性带来挑战;源码保护是个大问题;反人性的异步回调方式;包依赖混乱;没有吸引更多优秀的后端开发人员也是一个很重要原因,大量低效的代码加重CPU的负担,从而造成性能不行的假象;这一类的问题限制了Node.js的发展。
GO的任务调度器
老生常谈的问题,到了GO这里被换了一种思路来实现。
在移动互联网时代,海量连接迫使我们研发出能支持超高并发的系统。传统多线程的模式遇到了性能瓶颈,一个客户连接新建一个线程来处理,会消耗掉大量系统内存资源,一个线程大概需要新增2MB内存空间,大量线程切换还要带来上下文换页的开销,这明显跟不上时代的需求。于是就出现了两种处理高并发的解决思路:
- Netty和Node.js为代表的主线程+异步IO事件回调编程模型
- Go为代表的多协程调度+同步IO编程模型
前面已经简单介绍了Node.js这种异步编程模型,一个主线程处理所有请求,省去了上下文切换的开销。Go的思路则是既然线程占用资源太多,而且频繁线程切换带来CPU缓存不命中的开销,那我就想办法降低这些方面的影响。
于是Go巧妙的在运行时中设计了一套自己的资源调度器。他将自己要处理的任务封装成协程的概念,就是一个个goroutine,简写成G;同时设计了一个线程缓冲池,里面存放操作系统内核态线程,这些线程简称M;然后设计了一个逻辑处理器的概念叫P,用来撮合或拆分M与G,MG一旦成功匹配就利用M的CPU时间片来执行G的任务;拆分之后M回线程池可供其它P调度使用,G也可以找不同的P挂靠等待分配新的M继续后面的任务。
一切都很灵活,Go语言调度器会根据自己的调度算法,高效的处理所有G的任务队列。这种关系简写成GMP模型。下图是这个关系的简单说明:
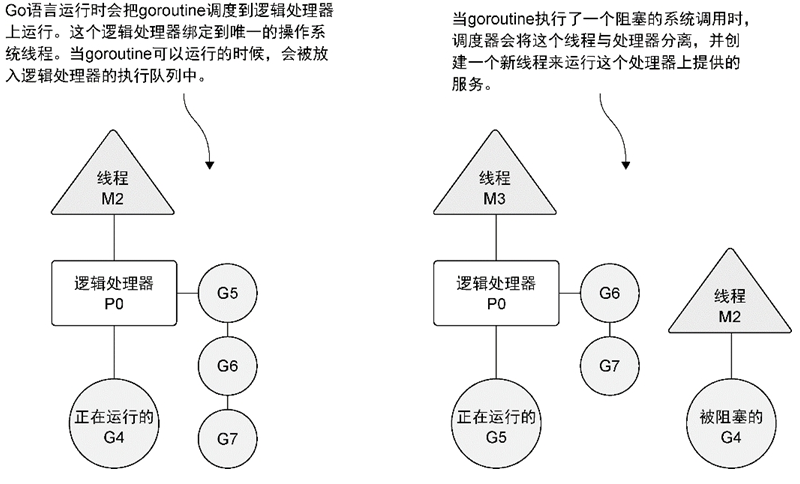
这里的IO操作是非网络IO操作,网络IO操作的量更大不可能用这条模型来处理,否则要分配的系统线程依然很多,程序很快就爆满了。网络IO操作都需要依赖底层操作系统提供的高并发处理接口来实现,比如Linux目前用的最多的就是epoll接口,批量处理网络IO事件,无论什么样的技术都逃不过操作系统底层这套API接口。
为了更高效的处理海量的网络IO事件,Go底层封装了一套网络轮询器,在Linux平台是基于epoll的IO多路复用模型来处理,此时M2和G4分离即可,G4进入网络轮询器待网络轮询器唤醒,M2继续绑定在P0上处理其它G。然而其它IO处理,比如本地文件读写,会采用上面M2和G4整体脱离P0的方式,P0申请新的M3来处理排队中的G,M2等G4阻塞完成之后再分离,G4进入排队,M2被回收等待再利用。
话说回来,Go这样的设计有啥特点呢?
- 抽象掉了操作系统级别的多线程并发模型,不是函数层面的封装,是编程模型的封装。
- 可以充分利用处理器多核并行执行能力,尽快分发任务。
- 协程足够轻量,上下文切换对CPU的开销极小。
- 相比NIO异步编程,代码编写更符合人类思维。
思考
提个问题,Go的这种模型会比Node.js和Netty更高效吗?
不要把Go想的这么美好,看下这篇文章:https://zhuanlan.zhihu.com/p/341931729
总结
搞清楚下面几个概念。
| 概念 | 说明 |
|---|---|
| 进程 | 一个程序对应一个独立程序空间 |
| 线程 | 一个执行空间,一个进程可以有多个线程,其中必须有一个主线程。 |
| 逻辑处理器 | 执行创建的goroutine,绑定一个内核线程 |
| 调度器 | Go运行时中的,分配goroutine给不同的逻辑处理器 |
| 全局运行队列 | 所有刚创建的goroutine都会放到这里 |
| 本地运行队列 | 逻辑处理器的goroutine队列 |
| 网络轮询器 | goroutine和逻辑处理器分离,绑定到网络轮询器队列 |
参考:协程为什么比线程轻量:/2021/10/12151539-go-thread-gmp.html
(完)
- 原文作者: 闪电侠
- 原文链接:https://chende.ren/2020/12/27221039-008-gmp-model.html
- 版权声明:本作品采用 开放的「署名 4.0 国际 (CC BY 4.0)」创作共享协议 进行许可