002 | 时序数据库
时序数据库全称为时间序列数据库。指主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。
在过去的十年间,我们亲历了关系型、非关系型、在线分析处理(OLAP)型、以及在线事务处理(OLTP)型数据库的市场之争,根据DB-Engines的一项针对数据库管理系统调查的统计,时序型数据库(time series database,TSDB)是自2020年以来,增长最快的数据库类型之一。
实时数据库
实时数据库本质是实时系统和数据库技术相结合的产物。它包括数据库,但不只是一个数据库,更是一个系统。
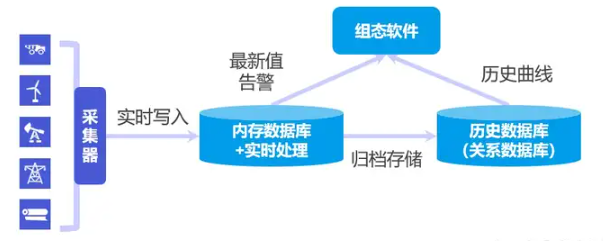
时序数据库
时序数据库是一种专门管理时间序列数据,也就是带时间标签的数据的数据库,尤其适用于工业物联网场景。
时序数据主要由工业机器、设备的传感器实时产生。这些时序数据包括工程领域桥梁的支座位移、振动,车联网领域汽车的车速、发动机转数,能源领域发电风车的功率、风速等等。
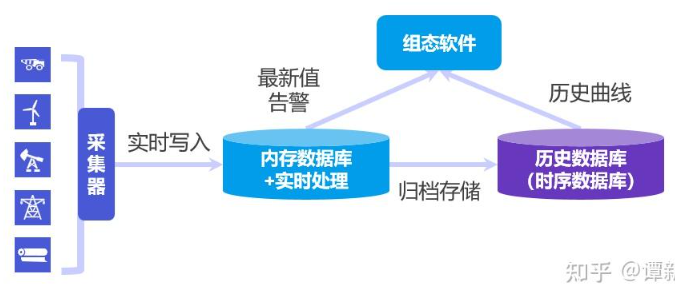
工业监控需求中的设备数量很多,导致产生的时序数据数据量非常庞大,采集频次也非常高。因此在实时数据库之外,出现了专门解决时序数据管理难点的数据库,也就是时序数据库。
上面说美国诞生了第一个实时数据库,如今中国也涌现出很多高性能的时序数据库,比如技术发源于清华,国产全自研的 IoTDB。
对应到实时数据库的逻辑,时序数据库是和关系型数据库等价的,因此可以无缝替代实时数据库中的历史数据库组件。
相比实时数据库中的历史数据库,时序数据库的性能可以领先 1-2 个数量级,在写入时序数据吞吐量、时序数据空间占用的压缩比、时间维度相关的查询耗时等方向,都具备优势。
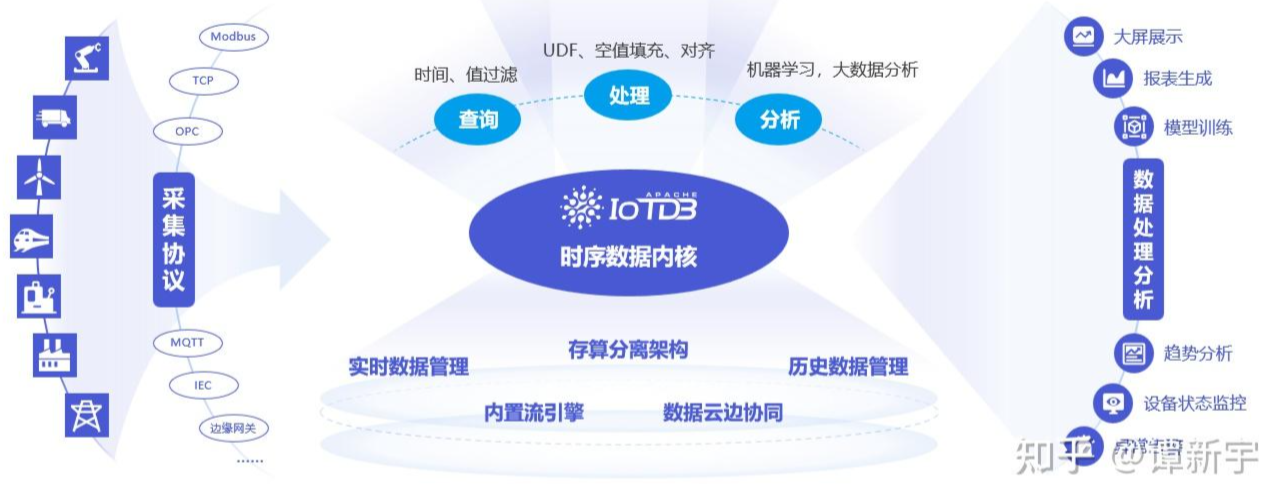
时序数据库和实时数据库对比
时序数据库和实时数据库的性能区别,主要有以下几点:
- 数据类型:时序数据库主要关注时序数据的处理,实时数据库可以处理时序数据以外的数据,重点关注广义上实时数据的更新。
- 数据架构:时序数据库通常使用专门针对时序数据的数据结构和存储技术,比如 IoTDB 使用的是自研的树形时序模型,以实现设备结构的直观对应,并结合列式存储文件格式 TsFile,实现海量时序数据的高压缩比和高效检索。实时数据库则支持通用的数据模型。
- 写入性能:时序数据库重视针对高通量、高并发的时序数据优化写入性能,比如 IoTDB 以列为整体进行写入,能够实现千万级写入吞吐,和高频数据的毫秒级接入。实时数据库则更侧重于工业数据整体的写入性能。
- 查询性能:时序数据库支持针对时序数据的特性查询与计算,例如 IoTDB 可支持降采样查询、最新点查询、时序分段查询等。实时数据库则注重实时查询和数据更新,例如实时查询在线用户的信息等。
- 数据分析能力:时序数据库通常与数据分析工具集成紧密,例如 IoTDB 涵盖内生机器学习节点 AINode,基于多类算法和自研模型,能够支持序列预测、异常预测等数据分析。实时数据库更侧重于实时数据处理。
- 扩展性:传统实时数据库多为主备部署架构,通常要求较高配置的机器,来追求单机的高性能;同时会对运行软件的稳定性要求较高,基本由高质量的代码来保证运行的稳定。而像时序数据库 IoTDB 实现的分布式架构,可以让系统轻松地实现水平扩展、秒级扩容;并且在保证稳定性的基础上,让数据库不再依赖昂贵的硬件和存储设备也能实现高可用,消除单点瓶颈/故障,大大降低了使用成本。
- 部署模式及协同性:随着本地储存工业数据的成本逐渐增加以及云服务的成熟,工业数据上云并实现端边云数据灵活同步的必要性逐步显现。以 IoTDB 为代表的时序数据库拥抱上云大趋势,通过统一的数据文件格式实现端边云数据协同同步,充分利用了边云算力资源。而传统实时数据库多采用私有化部署模式,运维成本往往较为高昂。
常用时序数据库性能对比
对比1
| DB名称 | 版本 | 写入速度(rows/s) | 存储开销(GB) | cpu开销 |
|---|---|---|---|---|
| InfluxDB | v1.8.10 | 80000 | 5.2 | 大部分时候打满 |
| Victoriametrics | v1.93.5 | 350000 | 15 | 大部分时候打满 |
| Elasticsearch | v8.10.4 | 200000 | 48.3 | 大部分时候打满 |
| Clickhouse | v22.6.9.11 | 520000 | 17 | 100~200% |
从测试结果来看,Clickhouse 写入速度最快,VM 次之,ES 经过调优后写入速度尚可,反而是号称行业标杆的 InfluxDB 写入最慢。不得不说的是,InfluxDB 的数据压缩做得最好,压缩倍数为 40 倍,Elasticsearch 压缩倍数最差,不到 5 倍,其他两个尚可。
从 CPU 开销来看,Clickhouse 最优,只用到 1 到 2 个核,CPU 消耗可谓极低,其他三款数据库大部分时候都将资源耗尽,只有在刷数据或者后台 Compaction 时,由于 IO 瓶颈,使得 CPU 没有打满。
参考阅读:
https://zhuanlan.zhihu.com/p/673333930
对比2
再来看一组InfluxDB,MySQL,Clickhouse对海量数据的存取性能测试,直接上结论:

ClickHouse 的优缺点
- 优点:极致的查询分析性能,较低的存储成本,高吞吐的数据写入,多样化的表引擎,完备的 DBMS 功能;
- 缺点:不支持事务,不支持真正的删除/更新,分布式能力较弱;不支持高并发,官方建议 QPS 为100;非标准的 SQL,join 的实现比较特殊,且性能不好;频繁小批量数据操作会影响查询性能;
目前还没有一个 OLAP 引擎能够满足各种场景的需求,其本质原因是,没有一个系统能同时在查询效率、时效性、可维护性三个方面做到完美,只能说 ClickHouse是为了极致查询性能做了一些取舍。
ClickHouse优缺点都很明显,是否采用还是要取决于和实际业务场景的契合度,适合自己的架构才是最好架构。
参考阅读:
https://baijiahao.baidu.com/s?id=1741159036488966111
总结
参考阅读:
https://zhuanlan.zhihu.com/p/699133760
(完)
- 原文作者: 闪电侠
- 原文链接:https://chende.ren/2024/10/11001437-001-timing-db.html
- 版权声明:本作品采用 开放的「署名 4.0 国际 (CC BY 4.0)」创作共享协议 进行许可