Go杂谈 | Protobuf、MsgPack等常见协议
JSON以其清晰明快横行,但网络大批量传输数据,序列化反序列化的场景下,和Protobuf这种数据传输协议相比,性能却不尽人意。为了解决JSON编解码性能差的问题,MsgPack给了我们新的选择。
JSON协议
菜鸟教程:https://www.runoob.com/json/json-syntax.html
JSON 的两种结构:
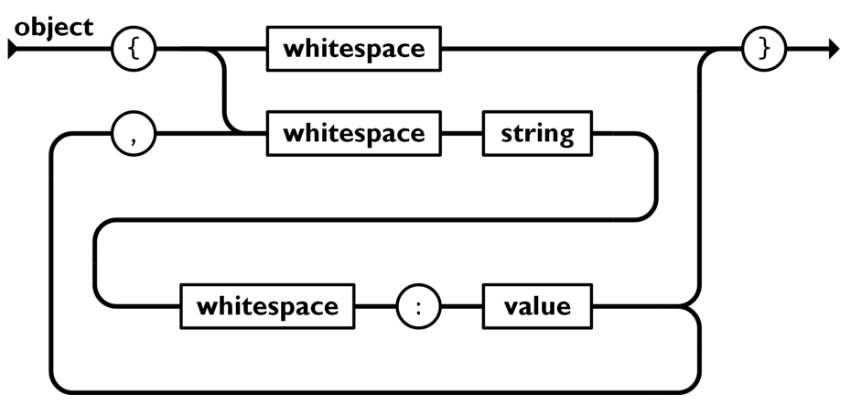
1、对象:大括号 {} 保存的对象是一个无序的名称/值对集合。一个对象以左括号 { 开始, 右括号 } 结束。每个"键"后跟一个冒号 :,名称/值对使用逗号 , 分隔。
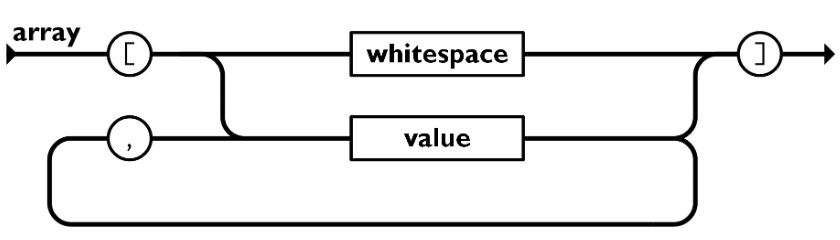
**2、数组:**中括号 [] 保存的数组是值(value)的有序集合。一个数组以左中括号 [ 开始, 右中括号 ] 结束,值之间使用逗号 , 分隔。
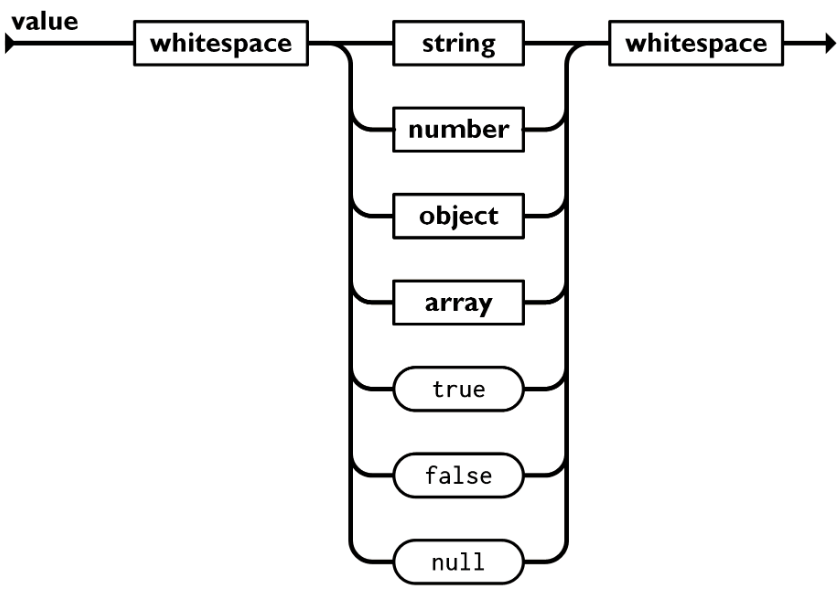
值(value)可以是双引号括起来的字符串(string)、数值(number)、true、false、 null、对象(object)或者数组(array),它们是可以嵌套。
JSON转义字符
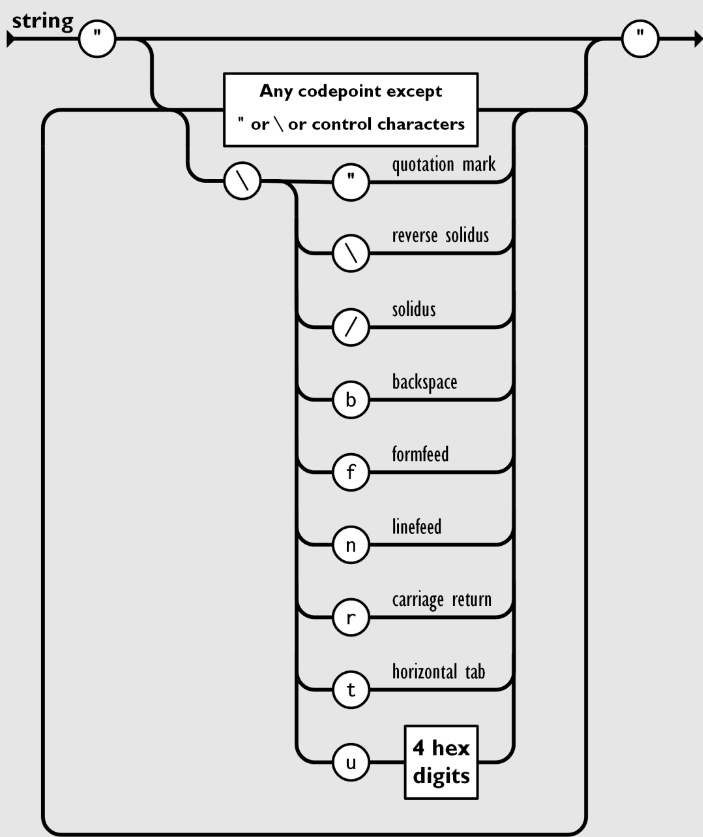
JSON 中字符串针对于特殊字符需要 JSON 转义,它使用反斜杠 \ 进行转义。JSON 序列包括 \\、\"、\/、\b、\f、\n、\r、\t ,或者 Unicode16 进制转义字符(比如 \uD83D\uDE02 ),JSON 字符串为 UTF-8 编码。
Protobuf协议
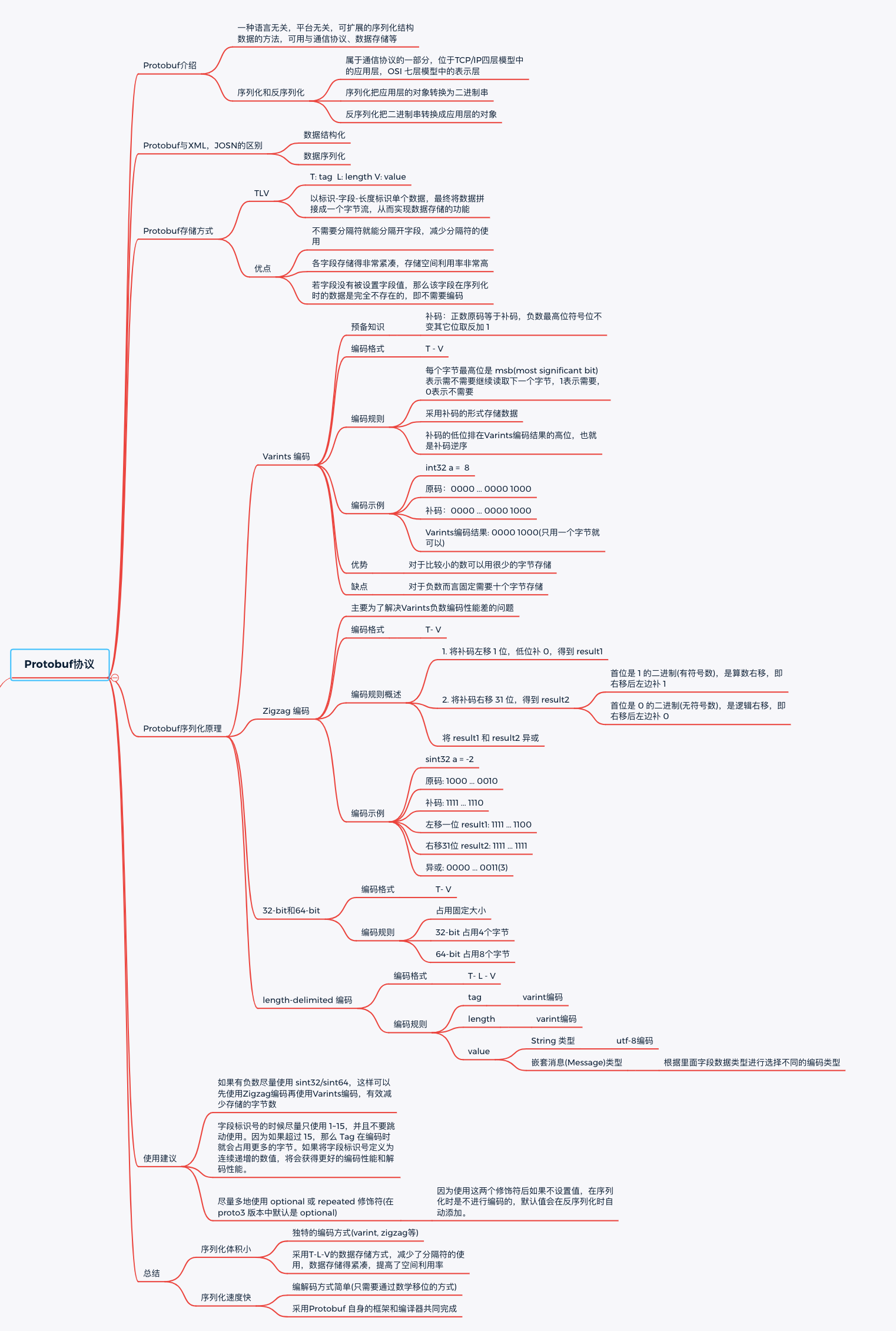
编码规则示意图:
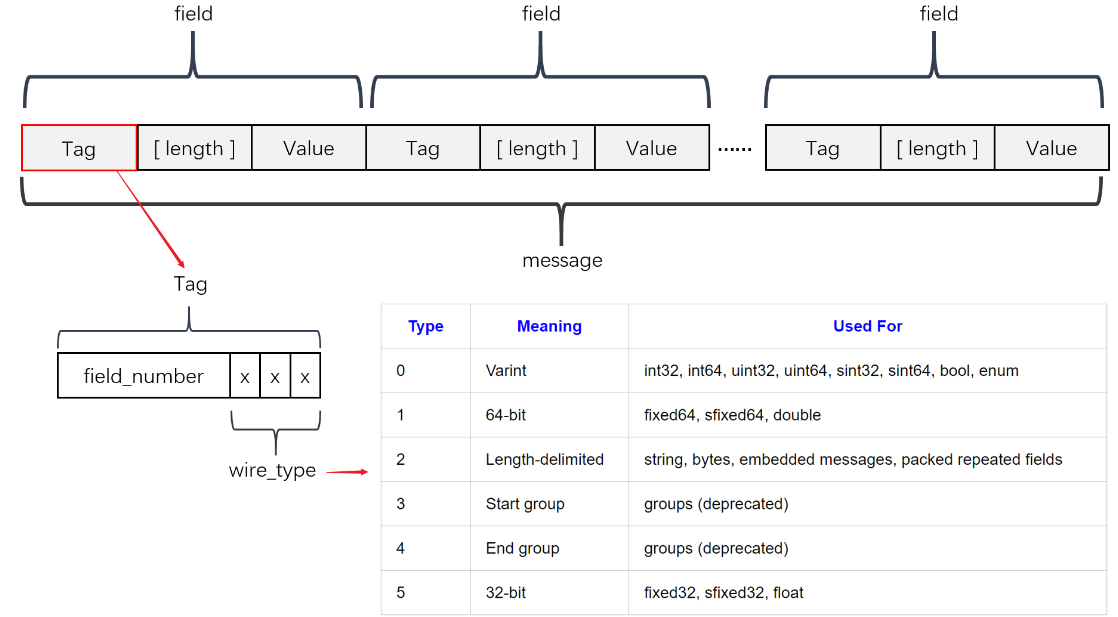
参考阅读:
https://www.cnblogs.com/zhangguicheng/p/14117962.html
https://brands.cnblogs.com/tencentcloud/p/12333
MsgPack协议
messagepack的数据类型主要分类两类:固定长度类型和可变长度类型。
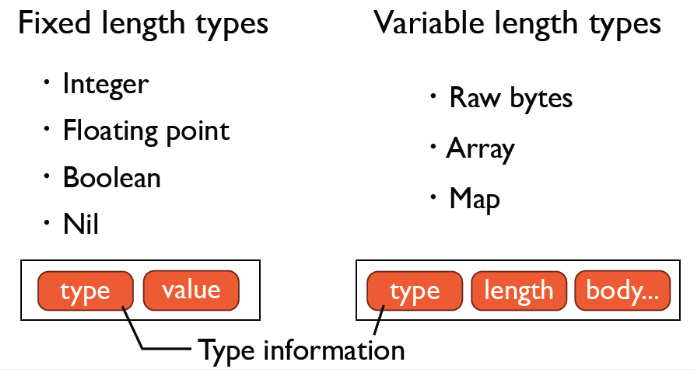
Formats Overview
| format name | first byte (in binary) | first byte (in hex) |
|---|---|---|
| positive fixint | 0xxxxxxx | 0x00 - 0x7f |
| fixmap | 1000xxxx | 0x80 - 0x8f |
| fixarray | 1001xxxx | 0x90 - 0x9f |
| fixstr | 101xxxxx | 0xa0 - 0xbf |
| nil | 11000000 | 0xc0 |
| (never used) | 11000001 | 0xc1 |
| false | 11000010 | 0xc2 |
| true | 11000011 | 0xc3 |
| bin 8 | 11000100 | 0xc4 |
| bin 16 | 11000101 | 0xc5 |
| bin 32 | 11000110 | 0xc6 |
| ext 8 | 11000111 | 0xc7 |
| ext 16 | 11001000 | 0xc8 |
| ext 32 | 11001001 | 0xc9 |
| float 32 | 11001010 | 0xca |
| float 64 | 11001011 | 0xcb |
| uint 8 | 11001100 | 0xcc |
| uint 16 | 11001101 | 0xcd |
| uint 32 | 11001110 | 0xce |
| uint 64 | 11001111 | 0xcf |
| int 8 | 11010000 | 0xd0 |
| int 16 | 11010001 | 0xd1 |
| int 32 | 11010010 | 0xd2 |
| int 64 | 11010011 | 0xd3 |
| fixext 1 | 11010100 | 0xd4 |
| fixext 2 | 11010101 | 0xd5 |
| fixext 4 | 11010110 | 0xd6 |
| fixext 8 | 11010111 | 0xd7 |
| fixext 16 | 11011000 | 0xd8 |
| str 8 | 11011001 | 0xd9 |
| str 16 | 11011010 | 0xda |
| str 32 | 11011011 | 0xdb |
| array 16 | 11011100 | 0xdc |
| array 32 | 11011101 | 0xdd |
| map 16 | 11011110 | 0xde |
| map 32 | 11011111 | 0xdf |
| negative fixint | 111xxxxx | 0xe0 - 0xff |
Avro协议
参考阅读:
https://blog.csdn.net/be_racle/article/details/134961707
https://tech.meituan.com/2015/02/26/serialization-vs-deserialization.html
CBOR协议
在百度查询到的CBOR协议规范,参考如下:
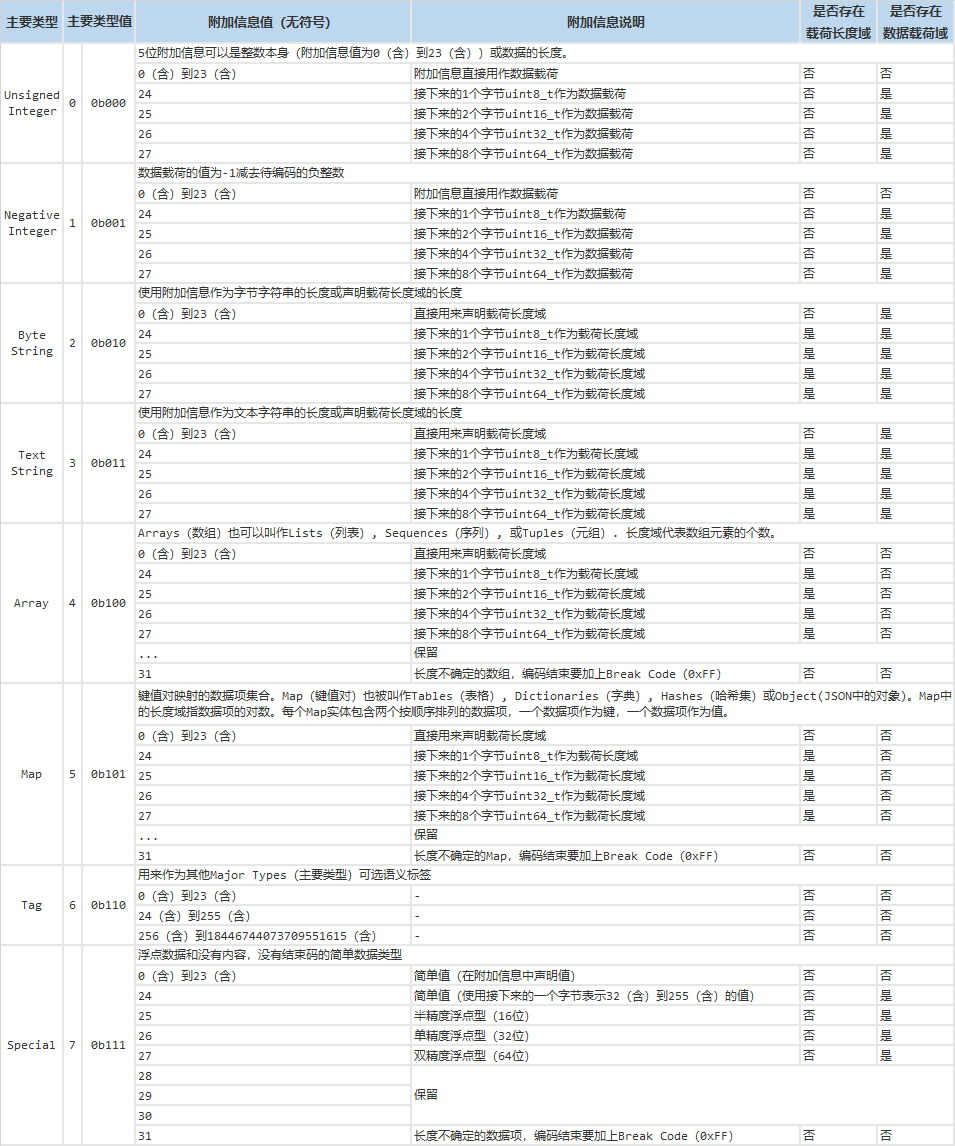
参考阅读:
https://baike.baidu.com/item/CBOR/22296344
https://www.jianshu.com/p/76adec5e61f8
Arrow协议
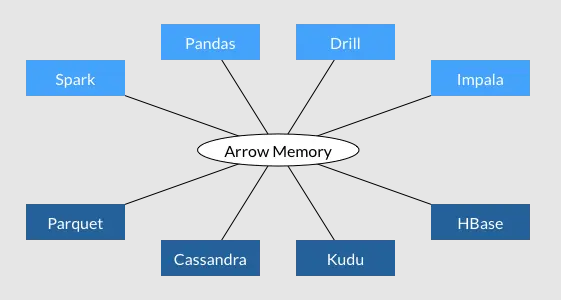
Apache Arrow 做为今后的标准数据交换格式,各个数据分析的系统和应用之间的交互性可以说是上了一个新的台阶。过去大部分的 CPU 周期都花在了数据的序列化和反序列化上,现在我们则能够实现不同系统之间数据的无缝共享。这意味着用户在将不同的系统结合使用时再也不用为数据格式多花心思了。
将传统的行存储转换成列储存,充分利用CPU 和 GPU 多核并行特点(单指令多数据SIMD/Single Instruction Multiple Data)。
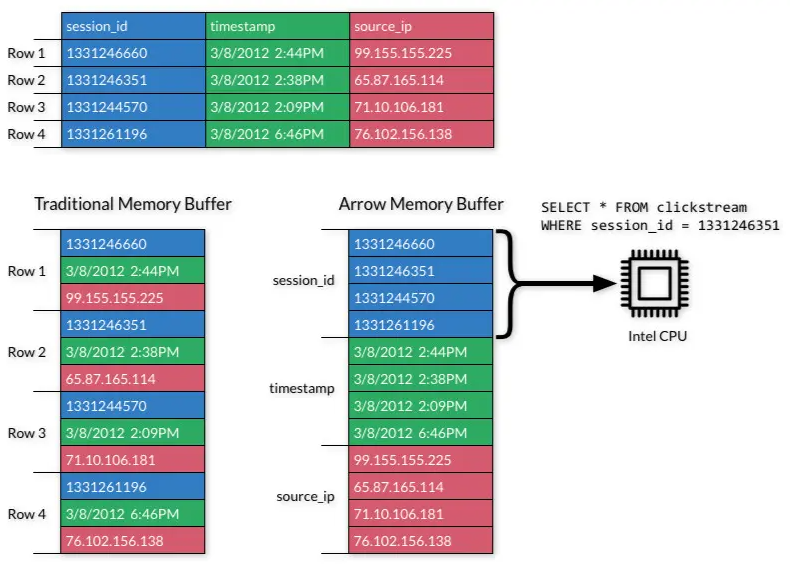
- 每个系统都有自己内部的内存格式
- 70-80% 的 CPU 浪费在序列化和反序列化过程
- 类似功能在多个项目中实现,没有一个标准
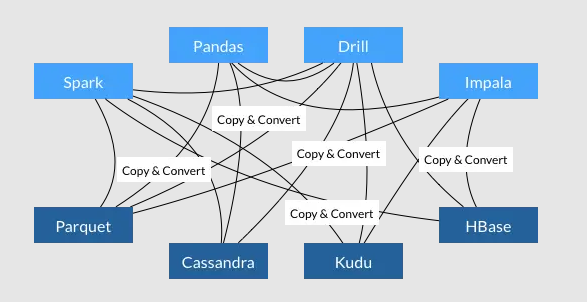
- 所有系统都使用同一个内存格式
- 避免了系统间通信的开销
- 项目间可以共享功能(比如 Parquet-to-Arrow reader)
参考阅读:https://segmentfault.com/a/1190000044161725
其它协议比较
Cap’n Proto 需要定义数据格式文件,无4G限制,支持引用,零复制,支持RPC
CBOR 不需要定义格式文件,无4G限制,支持引用,零复制。但是实现的库效率很差,O(n^2)
eXternal Data Representation (XDR) 支持RPC。Py的官方库内置了
Apache Avro 需要定义数据格式文件,无4G限制,支持引用,支持RPC。官方没有支持JS,第三方支持有
Apache Arrow 有4G限制,不支持引用,零复制。官方即将支持JS
msgpack 有4G限制,不支持引用,零复制。支持JS
Binn 有4G限制,不支持引用,零复制。支持JS
FlatBuffers 需要定义数据格式文件,空间有4G限制,只在buffer内支持引用,零复制
Colfer 需要定义数据格式文件,不支持枚举类型,零复制
Fast Binary Encoding 需要定义数据格式文件,有4G限制,不支持引用,零复制
feather 基于Apache Arrow,有4G限制,不支持引用,零复制。项目最后版本是2011年,太旧了
Transit 基于msgpack和JSON,有4G限制,不支持引用,零复制
Efficient XML Interchange (EXI) 和 Fast Infoset 都需要定义数据格式文件。这两种国际标准化的XML二进制方案都没有太流行的Py库
VelocyPack 是 图数据库ArangoDB 支持的序列化库。不需要定义格式文件,无4G限制,弱支持引用,零复制。可惜只是C++库,没有官方支持Py
更多参考资料
文档地址:
https://github.com/msgpack/msgpack/blob/master/spec.md
JSON、MessagePack、Protobuf、Thrift比较:
https://developer.aliyun.com/article/229784
读书:数据的编码和演进
https://zhuanlan.zhihu.com/p/499439715
https://zhuanlan.zhihu.com/p/518312160
https://zhuanlan.zhihu.com/p/538930071
参考阅读:
https://www.cnblogs.com/gjc917/p/15492469.html
https://cloud.tencent.com/developer/article/1489591
https://baijiahao.baidu.com/s?id=1752354372496700505
https://tech.meituan.com/2015/02/26/serialization-vs-deserialization.html
问题来了
Protobuf编解码高效,适合大批量数据的交换传输,但收发双方必须约定一致的schema文件,没有schema文件,数据将无法解析而失去意义,这让Protobuf很少被应用在数据存储领域;再者在业务需求频繁变更的场景中,很难想象要做多少工作来保证收发双方的协同。归根结底的原因是Protobuf格式的数据无法”自证清白“。
JSON可以灵活的表达,但是编解码效率实在太低,不适合大批量业务数据传输存储。
MsgPack比较好的解决了性能和表达清晰灵活的问题;但是编码规则稍显复杂,无论是数据大小还是编解码性能都没有Protobuf出色。这限制了MsgPack的大规模使用。
有没有这样的数据编解码方案:
- 不需要额外的schema文件,有数据就能正确解析。
- 编码后的数据小,而且编解码性能足够好。
- 规则简单,容易实现优秀的编解码库。
期待新的变化。
(完)
- 原文作者: 闪电侠
- 原文链接:https://chende.ren/2023/03/21124440-003-json-rpc.html
- 版权声明:本作品采用 开放的「署名 4.0 国际 (CC BY 4.0)」创作共享协议 进行许可