微服务004 | 缓存设计
在整个计算机科学中,缓存的概念无处不在。很大程度上是硬件资源成本和收益关系决定的。比如现代CPU都内置了三级缓存,现代计算机常见的硬盘->高速SSD->内存等逐级存储介质等。
应用程序如果要处理大量并发请求,没有有效的数据缓存策略,基本上是扛不住的。
缓存雪崩、击穿和穿透
一般我们将数据放入数据库中落地管理(比如MySQL),缓存直接用内存变量记录或者用分布式缓存工具(Redis)。数据缓存一旦涉及到更新或者过期时间等问题,都可能导致缓存雪崩、击穿、穿透的问题。下面先介绍这三种情况:
雪崩
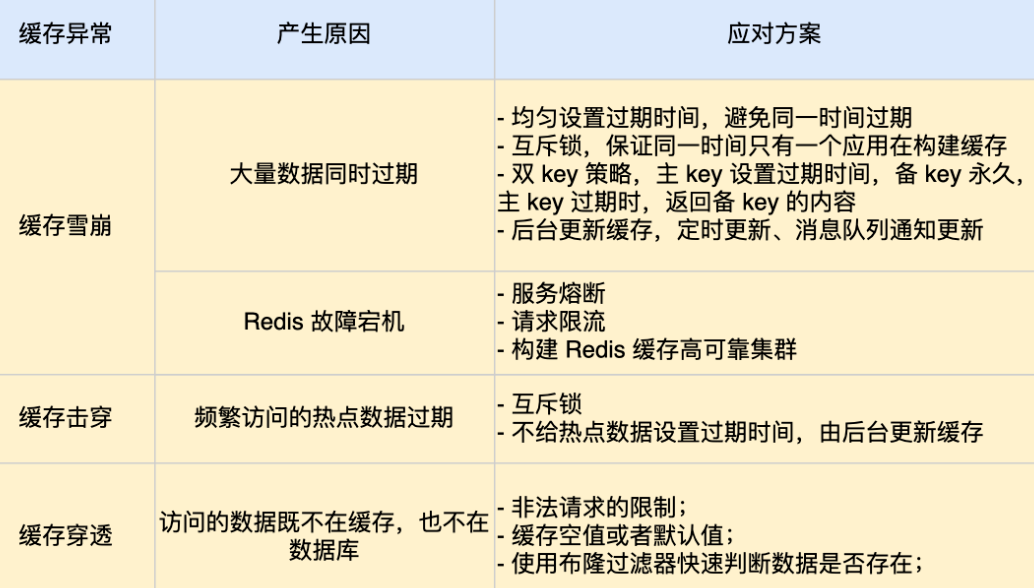
可以看到,发生缓存雪崩有两个原因:
- 大量数据同时过期;
- Redis 故障宕机;
不同的诱因,应对的策略也会不同。
针对大量数据同时过期而引发的缓存雪崩问题,常见的应对方法有下面这几种:
- 均匀设置过期时间;
- 互斥锁;
- 双 key 策略;
- 后台更新缓存;
针对 Redis 故障宕机而引发的缓存雪崩问题,常见的应对方法有下面这几种:
- 服务熔断或请求限流机制;
- 构建 Redis 缓存高可靠集群;
击穿
应对缓存击穿可以采取前面说到两种方案:
- 互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
穿透
缓存穿透的发生一般有这两种情况:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
- 黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
应对缓存穿透的方案,常见的方案有三种。
- 第一种方案,非法请求的限制;
- 第二种方案,缓存空值或者默认值;
- 第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;
布隆过滤器
我们可以在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行。
布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中。
布隆过滤器会通过 3 个操作完成标记:
- 第一步,使用 N 个哈希函数分别对数据做哈希计算,得到 N 个哈希值;
- 第二步,将第一步得到的 N 个哈希值对位图数组的长度取模,得到每个哈希值在位图数组的对应位置;
- 第三步,将每个哈希值在位图数组的对应位置的值设置为 1;
举个例子,假设有一个位图数组长度为 8,哈希函数 3 个的布隆过滤器。
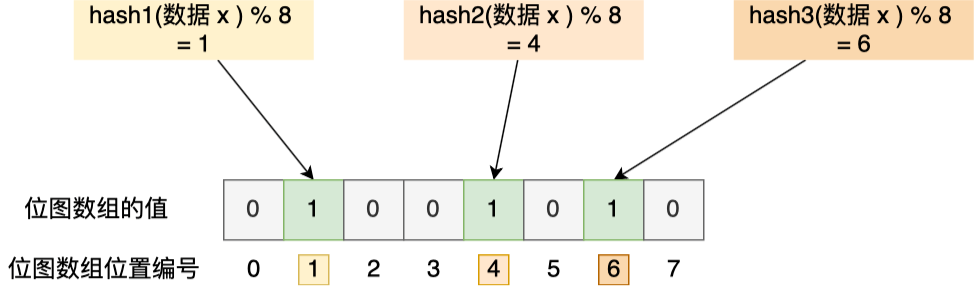
在数据库写入数据 x 后,把数据 x 标记在布隆过滤器时,数据 x 会被 3 个哈希函数分别计算出 3 个哈希值,然后在对这 3 个哈希值对 8 取模,假设取模的结果为 1、4、6,然后把位图数组的第 1、4、6 位置的值设置为 1。当应用要查询数据 x 是否数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中。
布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时存在哈希冲突的可能性,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
参考:
https://blog.csdn.net/qq_34827674/article/details/123463175
https://www.51cto.com/article/785894.html
一致性Hash
一致性hash算法主要应用在分布式缓存系统中,在增加或者删除服务器节点时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系,也就是系统中的大多数历史缓存的存储服务器节点可以不变,解决了普通hash算法带来的动态伸缩性问题。
一致性hash 通过引入虚拟节点解决了这个问题,每个实际节点映射多个虚拟节点,数据按照规则找到虚拟节点后,再储存到映射的实际节点上;因为虚拟节点可以在hash环上均匀分布,这意味着当一个真实节点失效退出后,它原来所承载的压力将会均匀地分散到其他节点上去,解决缓存雪崩问题
参考:
https://zhuanlan.zhihu.com/p/470368641
缓存更新策略
在分布式系统中,为了保证缓存与数据库双写一致性,可以采用以下方案:
读取操作:
- 先尝试从缓存读取数据,若缓存命中,则直接返回缓存中的数据。
- 若缓存未命中,则从数据库读取数据,并将数据放入缓存。
更新操作:
- 在更新数据时,首先在数据库进行写入操作,确保主数据库数据的即时更新。
- 为了减少数据不一致窗口,采用异步方式处理缓存更新,具体做法是监听数据库的binlog事件,异步进行删除缓存。
- 在一主多从的场景下,为了确保数据一致性,需要等待所有从库的binlog事件都被处理后才删除缓存(确保全部从库均已更新)。
同时,还需注意以下要点:
- 对于高并发环境,可能需要结合分布式锁、消息队列或缓存失效延时等技术,进一步确保并发写操作下的数据一致性。
- 异步处理binlog时,务必考虑异常处理机制和重试策略,确保binlog事件能够正确处理并执行缓存更新操作。
参考阅读:
https://zhuanlan.zhihu.com/p/629247043
https://zhuanlan.zhihu.com/p/444217985
(完)
- 原文作者: 闪电侠
- 原文链接:https://chende.ren/2022/04/08172659-004-cache.html
- 版权声明:本作品采用 开放的「署名 4.0 国际 (CC BY 4.0)」创作共享协议 进行许可