HTTP2简介
看这篇对gRPC讲解的文章:https://zhuanlan.zhihu.com/p/161577635
本文的内容都是来自上面文章的节选。
HTTP1.1的问题
HTTP1.1以其简单、可读性高、超高普及率、历史悠久,作为经典的存在,为互联网的普及做出了重要贡献。但在当今超高的流量、超高的使用频率背景下,打开一个页面动辄几十个请求,使得速度已经难以满足贪婪人类的需求。这主要表现在以下几个方面。
一、 冗余文本过多,导致传输体积很大 作为经典的无状态协议,它使得Web后端可以灵活地转发、横向扩展,但其代价是每个请求都会带上冗余重复的Header,这些文本内容会消耗很多空间,和更快传输的目标相左。
二、 并发能力差,网络资源利用率低 HTTP1.1 是基于文本的协议,请求的内容打包在header/body中,内容通过\r\n来分割,同一个TCP连接中,无法区分request/response是属于哪个请求,所以无法通过一个TCP连接并发地发送多个请求,只能等上一个请求的response回来了,才能发送下一个请求,否则无法区分谁是谁。
于是H1.1提出了一个pipeline的特性,允许请求方一口气并发多个request,但对服务方有一个变态的要求,需要对应的response按照request的顺序严格排列,因为不按顺序排列就分不清楚response是属于哪个request的。这给Proxy(Nginx等)带来了复杂性,同时如果第一个请求迟迟不返回,那后面的请求都会受影响,所以普及率不高。
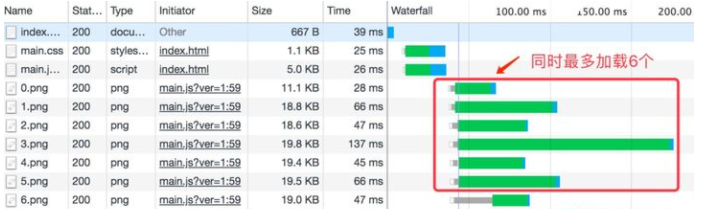
但当今的Web页面有玲琅满目的图片、js、css,如果让请求一个个串行执行,那页面的渲染会变得极慢。于是只能同时创建多个TCP连接,实现并发下载数据,快速渲染出页面。这会给浏览器造成较大的资源消耗,电脑会变卡。很多浏览器为了兼顾下载速度和资源消耗,会对同一个域名限制并发的TCP连接数量,如Chrome是6个左右,剩下的请求则需要排队,Network下的Waterfall就可以观察排队情况 (见下图右边的颜色条)。
HTTP1.1时,有6个并发连接,可以看到最下面三个请求在排队:
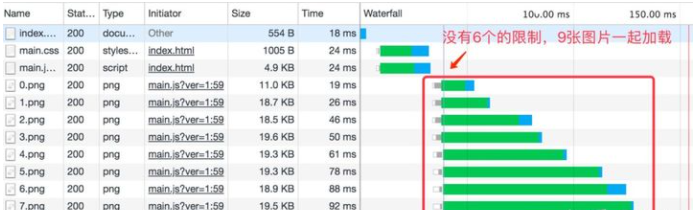
HTTP2中,可以看出请求时同时发出的,没有排队,且只占用一个连接:
狡猾的人类为了避开这个数量限制,将图片、css、js等资源放在不同域名下(或二级域名),避开排队导致的渲染延迟。快速下载的目标实现了,但这和更低的资源消耗目标相违背,背后都是高昂的带宽、CDN成本。
HTTP2 当救世主
H1.1 在速度和成本上的权衡让人纠结不已,HTTP2的出现就是为了优化这些问题,在更快的传输和更低的成本两个目标上更进了一步。有以下几个基本点:
- HTTP2 未改变HTTP的语义(如GET/POST等),只是在传输上做了优化
- 引入帧、流的概念,在TCP连接中,可以区分出多个request/response
- 一个域名只会有一个TCP连接,借助帧、流可以实现多路复用,降低资源消耗
- 引入二进制编码,降低header带来的空间占用
核心可分为 头部压缩 和 多路复用。这两个点都服务于 更快的传输、更低的资源消耗 这两个目标,与上文呼应。
Frame
Frame 是 HTTP/2 里面最小的数据传输单位,一个 Frame 定义如下:
+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+-------------------------------+
|R| Stream Identifier (31) |
+=+=============================================================+
| Frame Payload (0...) ...
+---------------------------------------------------------------+
- Length:也就是 Frame 的长度,默认最大长度是 16KB,如果要发送更大的 Frame,需要显式的设置 max frame size。
- Type:Frame 的类型,譬如有 DATA,HEADERS,PRIORITY 等。
- Flag 和 R:保留位,可以先不管。
- Stream Identifier:标识所属的 stream,如果为 0,则表示这个 frame 属于整条连接。
- Frame Payload:根据不同 Type 有不同的格式。
头部压缩
就是用编码的方式确定一些不变的header,在发送时只发送对应编码即可,减少传输。
具体又分固定的静态编码(61个),和不固定的动态编码(由CS端动态约定维护)。
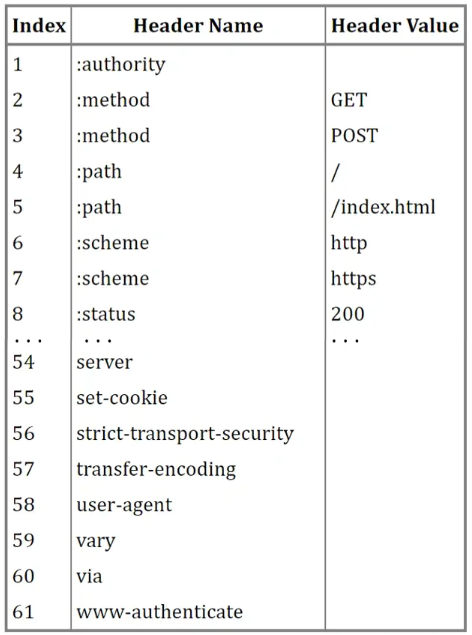
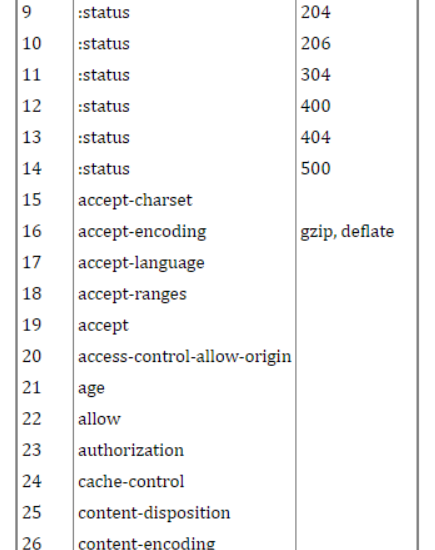
多路复用
H1.1核心的尴尬点在于,在同一个TCP连接中,没办法区分response是属于哪个请求,一旦多个请求返回的文本内容混在一起,就天下大乱,所以请求只能一个个串行排队发送。这直接导致了TCP资源的闲置。
HTTP2为了解决这个问题,提出了流的概念,每一次请求对应一个流,有一个唯一ID,用来区分不同的请求。基于流的概念,进一步提出了帧,一个请求的数据会被分成多个帧,方便进行数据分割传输,每个帧都唯一属于某一个流ID,将帧按照流ID进行分组,即可分离出不同的请求。这样同一个TCP连接中就可以同时并发多个请求,不同请求的帧数据可穿插在一起,根据流ID分组即可。这样直接解决了H1.1的核心痛点,通过这种复用TCP连接的方式,不用再同时建多个连接,提升了TCP的利用效率。 这也是多路复用思想的一种落地方式,在很多消息队列协议中也广泛存在,如AMQP,其channel的概念和流如出一辙,大道相通。
在HTTP2中,流是一个逻辑上的概念,实际上就是一个int类型的ID,可顺序自增,只要不冲突即可,每条帧数据都会携带一个流ID,当一串串帧在TCP通道中传输时,通过其流ID,即可区分出不同的请求。
HTTP/2 通过 流(Stream )支持了连接的多路复用,提高了连接的利用率。Stream 有很多重要特性:
- 一条连接可以包含多个 Streams,多个 Streams 发送的数据互相不影响。
- Stream 可以被 client 和 server 单方面或者共享使用。
- Stream 可以被任意一端关闭。
- Stream 会确定好发送 frame 的顺序,另一端会按照接受到的顺序来处理
- Stream 用一个唯一 ID 来标识。
PS: AMQP
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现有RabbitMQ等。
总结
参考阅读
https://www.lxiaoyu.com/p/204470
https://zhuanlan.zhihu.com/p/276057825
(完)